
4.测试Hadoop分布式集群环境;
首先在通过Master节点格式化集群的文件系统:

输入“Y”完成格式化:

格式化完成以后,我们启动hadoop集群

我们在尝试一下停止Hadoop集群:
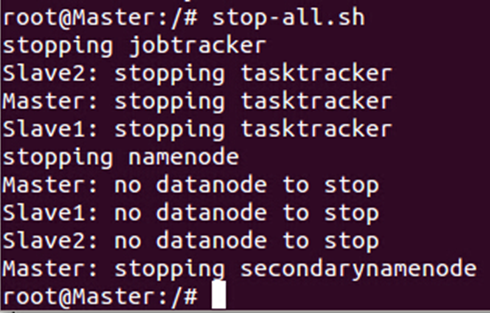
此时出现了“no datanode to stop”的错误,出现这种错误的原因如下:
每次使用 “hadoop namenode -format”命令格式化文件系统的时候会出现一个新的namenodeId,而我我们在搭建Hadoop单机伪分布式版本的时候往我们自己创建的tmp目录下放了数据,现在需要把各台机器上的“/usr/local/hadoop/hadoop-1.2.1/”下面的tmp及其子目录的内容清空,于此同时把“/tmp”目录下的与hadoop相关的内容都清空,最后要把我们自定义的hdfs文件夹中的data和name文件夹中的内容清空:

把Slave1和Slave2中同样的内容均删除掉。
重新格式化并重新启动集群,此时进入Master的Web控制台:

此时可以看到Live Nodes只有三个,这正是我们预期的,因为我们Master、Slave1、Slave2都设置成为了DataNode,当然Master本身同时也是NameNode。
此时我们通过JPS命令查看一下三台机器中的进程信息:

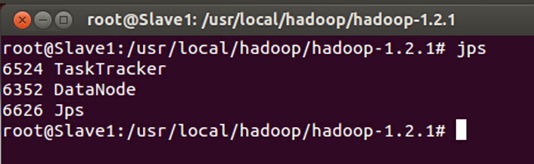

发现Hadoop集群的各种服务都正常启动。
至此,Hadoop集群构建完毕。